请谈一谈 Kafka 数据一致性原理?
发布于 2020-05-19 18:13:25
关注者
0
被浏览
927
1 个回答
-

一致性就是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
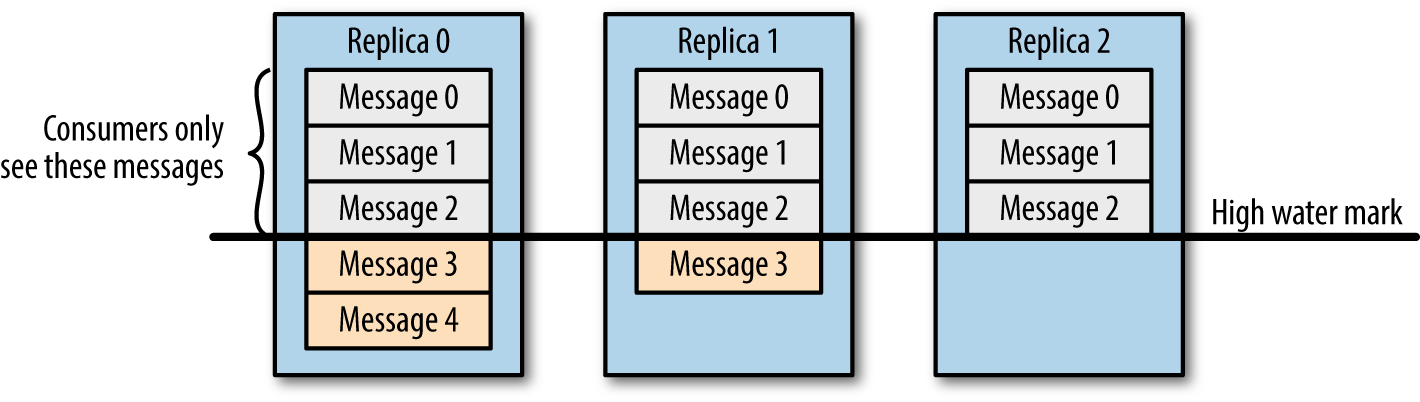
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop假设分区的副本为3,其中副本0是 Leader,副本1和副本2是 follower,并且在 ISR 列表里面。虽然副本0已经写入了 Message4,但是 Consumer 只能读取到 Message2。因为所有的 ISR 都同步了 Message2,只有 High Water Mark 以上的消息才支持 Consumer 读取,而 High Water Mark 取决于 ISR 列表里面偏移量最小的分区,对应于上图的副本2,这个很类似于木桶原理。
这样做的原因是还没有被足够多副本复制的消息被认为是“不安全”的,如果 Leader 发生崩溃,另一个副本成为新 Leader,那么这些消息很可能丢失了。如果我们允许消费者读取这些消息,可能就会破坏一致性。试想,一个消费者从当前 Leader(副本0) 读取并处理了 Message4,这个时候 Leader 挂掉了,选举了副本1为新的 Leader,这时候另一个消费者再去从新的 Leader 读取消息,发现这个消息其实并不存在,这就导致了数据不一致性问题。
当然,引入了 High Water Mark 机制,会导致 Broker 间的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。延迟时间可以通过参数 replica.lag.time.max.ms 参数配置,它指定了副本在复制消息时可被允许的最大延迟时间。